

2025年CES上插入系列,黄仁勋的主题演讲眩惑了许多留心,我也在第一时辰收看了在线直播。
不得不说,老黄当今手脚全球科技界的顶流,得胜让显卡这种东西跟着AI的爆火,从游戏玩家的话题造成了大家话题。
本文将带环球望望我庄重到的故兴致的三个片刻,并作念少量小小的诠释。
第一个片刻,络续单手持持的RTX50系显卡。
笔者手脚游戏玩家,最初会留心的便是RTX系列显卡了。在今日刚开场不久,黄仁勋就拿出来了RTX50系显卡了,其中5090最为引东谈主刺眼。

固然TGP从4090的450瓦提高到了575瓦,但单手持持意味着至少公版的5090不需要绝顶夸张的散热规格。非公版显卡的三电扇应该不错比拟好的压制温度。
固然5090的散热条目并不诟谇常过分。不外,1999好意思元的订价,32G的显存如故有点过于高冷了,显着根柢不是给游戏玩家准备的。

关于大多数东谈主来说,看到老黄说5070的性能等于4090就运行上面了,几乎便是看到了捡低廉的契机,不买一张5070比买了A股还痛苦。

而买了4090的网友听完就炸锅了,直呼:没猜测看个发布会,我的4090就只值5070的549刀了?
不外,你一定不错敬佩老黄的皮衣,老黄的刀法,但对老黄的这类描述一定要严慎对待。比如,当年就说过3070的性能不错跳跃上一代旗舰RTX 2080 Ti,内容上根柢不是那么回事。

有海外网友列出了两张卡的对比数据,看到这个,你还敢信老黄说的?最多便是部分参数性能能达到一个水平吧。总之别太上面,最佳过一阵子望望国行5070的价钱再说。
不外,我以为老黄此次CES上说的RTX 5090倒是还有一个故兴致的场合,要不是这位叫Jim Fan的大佬说,我也十足没庄重到。

他说,新一代显卡将使用神经网罗生成90%的游戏画面的像素,只须10%的像素使用传统的光辉跟踪算法来渲染像素。使用传统设施渲染的画面像草图,而显卡会凭据草图生成其他的画面细节像素,生成速率很快。
这就有点颠覆性了,生成式AI大模子出生于显卡,又再造了显卡。游戏显卡畴前叫GTX,RTX的定名便是在给光追作念践诺,以后RTX的定名是不是会凭据AI再作念一次修改呢?
除了生成更多像素,英伟达还复旧让显卡生成新的画面帧,传统运筹帷幄形状生成一个帧之后,用DLSS再生成三个帧。这将大大提高游戏的帧率,提高游戏画面的开放度。
以后还哪有什么玩游戏的显卡,就算你是在玩游戏,显卡也在不时的作念AI推理啊。
第二个兴致片刻,化身好意思国队长,展示GB200 NVL72的遒劲。
欧美伦理片a在线观看酒过三巡,先容完花消级显卡之后,在先容数据中心级B200显卡之前,老黄提到了三个Scaling Law。
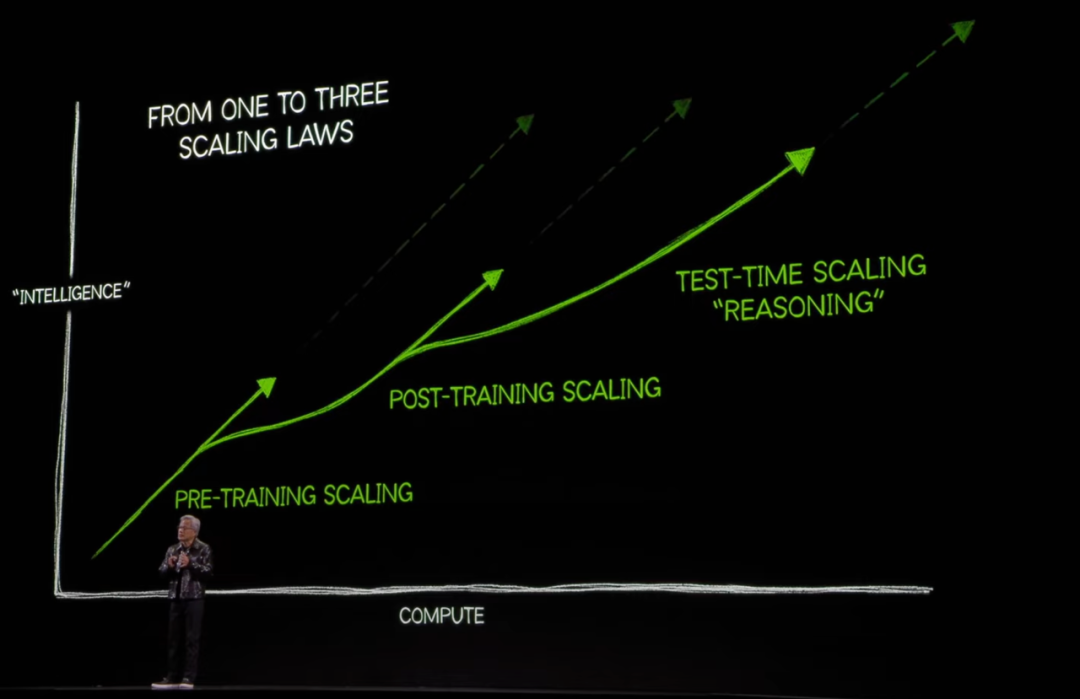
第一个是预教师阶段模子会跟着数据、算力和参数的擢升而擢升着力;
第二个是在教师完成后,通过微调、模子蒸馏等多样优化期间进行二次教师来擢升着力;
第三个则是在推理阶段,通过多要领的推理,雷同慢想考的形状来擢升模子的着力。

为什么强调这Scaling Law呢?因为这三个阶段齐需要渊博的B200这种级别的高性能显卡。
为了匡助环球了解这些有点乱的信息,这里先深刻几个观念。最初,新一代显卡的架构叫Blackwell,是以,显卡代号便是B200。
而常说的GB200其实是同期带有Grace CPU和Blackwell显卡的主板。如上图所示,便是一个超等芯片。严格来说,它叫NVL2,因为它有两个Blackwell显卡。

上图是一套NVL72机架系统,NVL72里是用NVLink开放了72块B200显卡,也便是36个NVL2的小的超等芯片。NVL72是史上最强 AI 运筹帷幄系统,领有 1.4 ExaFLOPS算力、14TB HBM内存、1330 万亿晶体管。
老黄声称,当前,多样规格的GB200 NVL系统也曾参预全面量产的阶段,主流的云行状商齐部署了。新的Blackwell显卡提供4倍能效、3倍资本优化,大幅镌汰 AI 教师和推理资本,将加快 AI 讹诈发展。

为了形象地先容这套NVL72有多夸张,老黄拿出了看着像好意思国队长一样的盾牌,摆出了好意思国队长的好汉姿势。
刚看见这块芯片面容的东西,我就径直懵了,这样大的芯片庄重的吗?主流的晶元最大才12英寸,这肉眼看着直径至少27寸泄露器那么大。

这样大一块超等芯片,散热要若何弄呢?我发现存这个狐疑的不仅仅我一个。老黄拿着这块芯片对着NVL72比划,让许多东谈主误以为,这是把这样大的芯片塞到这台NVL72机柜里了。

我也被老黄的这顿不测的饰演迷惑到了,有点懵。许多异邦网友齐有一样的嗅觉。有网友指出来,老黄手里拿的是一个谈具,展示的仅仅一台NVL72机柜顶用到的主要芯片放在沿途的神志。

委果NVL72的芯片不是这样制造出来的,更不是这样使用的。庞大网友请定心:要真有这样大的晶元,很可能不是台积电代工的,而是宇宙积电代工的,你不研讨一下良品率了,也得起码给他来点液氮作念散热标配了吧。
老黄这波师法好意思队的操作,总嗅觉要跟钢铁侠马斯克组CP了。
毕竟马斯克当前的AI公司xAI,还有具有自动驾驶智力的特斯拉汽车,还有东谈主形机器东谈主擎天柱,齐需要用到老黄的显卡。马斯克用英伟达显卡便是最佳的背书之一,毕竟马斯克是最懂若何把钱花在刀刃上的。
话说归来,老黄的独特安排不仅仅这个谈具。他声称,这一块超等大芯片,也便是一台NVL72,能提供1.4ExaFlops的算力,ExaFlops什么观念?这未便是前几年一直在说的,全球许多超算追求的发展磋磨吗?
老黄也说了,畴前超算数据中心里一所有这个词这个词房子的行状器加起来智力达到的算力水平,当今一台NVL72就作念到了,惊不惊喜。况兼1.2PB的内存带宽十分于一所有这个词这个词互联网的带宽,你就说吓不吓东谈主。

如实吓东谈主,不外,我庄重到,老黄说的1.4ExaFlops的算力,算力精度用FP4这个超低精度来运筹帷幄的,要知谈,当今的E级HPC超等运筹帷幄机的单元是FP64双精度啊,老黄你有点不憨厚啊。
诸君看官,不要的确以为一台GB200 NVL72就能顶E级超算了。
第三个兴致片刻,DGX-1微缩成桌面级电脑。
2016年,老黄当着马斯克还有OpenAI主要首创东谈主的面,把第一代DGX-1委派给了OpenAI,2022年,OpenAI成了率领全球走进生成式AI期间时间的领会东谈主。

老黄径直暗示,这样一台机架级别的行状器如故太大了,为了让AI研发者,数据科学家,学生和开导者齐不错在桌子上摆放一台超等运筹帷幄机,必须得把它的尺寸变小。

英伟达书记启动名为DIGITS(Deep learning gpu intelligence training system)的技俩,打造桌面级超等运筹帷幄机,它将基于全新的GB10超等芯片打造,可提供1 Petaflop的AI 运筹帷幄性能,可推理2000亿参数大模子。

它是作念什么用的呢?开导者在土产货用它完成模子原型开导后,不错把模子放到云大致其他数据中心进行教师,模子教师完成后不错放到土产货进行微调大致推理。
由于土产货和云上齐取舍了Grace Blackwell 架构和 NVIDIA AI Enterprise 软件平台,作念到了软硬件的无缝相接。
这应该是英伟达初度提到GB10超等芯片,它是基于Grace Blackwell架构打造的SoC,在 FP4 精度下可提供高达1 Petaflop 的 AI运筹帷幄性能。GB10还集成了20核的Arm解决器,两者通过NVLink-C2C芯片互连期间互一样达。

每台建造可提供128GB的分享内存,不外,它既不是GDDR显存,也不是HBM,而是DDR5X内存,是以没法径直跟5090大致B200进行对比。不外,手脚一款桌面级建造,功耗和散热并不高,也没法奢求能用上显存。
老黄暗示,凭借128GB的分享内存,它不错运行最高2000亿参数的大型谈话模子。和谐英伟达的ConnectX网罗期间,能把两台建造连在沿途,这样就不错推理4050亿参数的AI模子。
只不外,它的推感性能会不如预料的那么好。
有东谈主量化之后用单张24G显存的4090推理了70B的大模子,每秒14个Token。换成32G的5090表面上能更快,但应该如故不可推理2000亿参数的大模子。
是以,一些准备买5090运行土产货大模子的用户,可能需要在两者之间衡量一下了。一台这样的桌面级建造提倡零卖价为3000好意思元,仅比单块RTX 5090的售价高了1000好意思元。
研讨到他能放在桌面上,也就镌汰了所有这个词世俗东谈主在土产货玩大谈话模子的最低的门槛插入系列,如故挺故兴致的。